1. Introduction
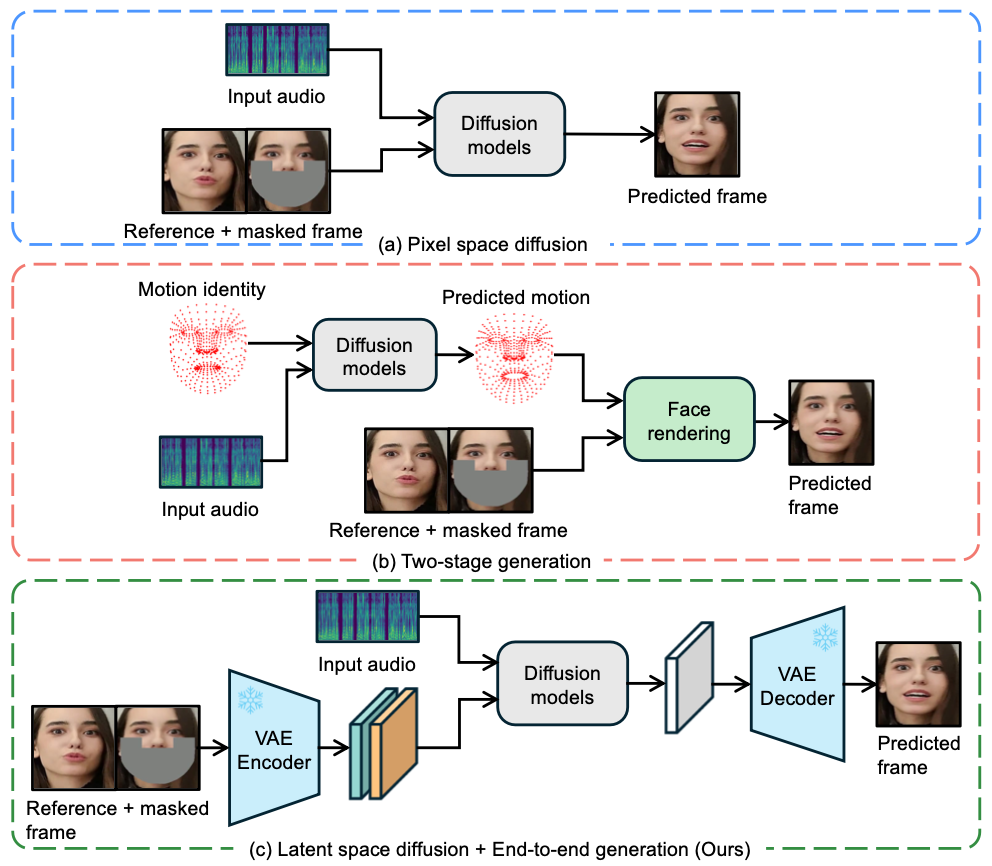
2. Related Work
2.1. Diffusion-based Lip Sync
Diff2lip
DiffusionVideoEditing
MyTalk
StyleSync
Diffdub
2.2. Non-diffusion-based Lip Sync
Wav2Lip
Generating Ultra-High Resolution TalkingFaces
StyleSync
VideoReTalking
DINet
MuseTalk
Generating Ultra-High Resolution TalkingFacesAnchit Gupta, Rudrabha Mukhopadhyay, Sindhu Balachandra, Faizan Farooq Khan, Vinay P Namboodiri, and CV Jawahar. Towards generating ultra-high resolution talking-face videos with lip synchronization. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5209–5218, 2023.
3. Method
3.1. LatentSync Framework
Audio layers
SyncNet supervision
PREVIOUSSystems of Linear Equations